
 Гостей: 18
Гостей: 18- 14.12.2012 09:28
- Разное
 Визуальный поиск становится столь же важной составляющей "всемирной паутины", как и традиционный текстовый. Однако существующие на сегодня решения не всегда могут достойно ответить на запросы пользователей. Какие технологии дадут реальную эффективность? Рассмотрим реалии рынка.
Визуальный поиск становится столь же важной составляющей "всемирной паутины", как и традиционный текстовый. Однако существующие на сегодня решения не всегда могут достойно ответить на запросы пользователей. Какие технологии дадут реальную эффективность? Рассмотрим реалии рынка.
Более половины объема головного мозга используется для распознавания визуальных образов. Сложнее всего при этом определить контекст видимого изображения, то есть ответить на вопрос "Что это?" Ведь для этого ведь нужно сопоставить полученное изображение с миллионом образов, накопленных в процессе развития и обучения.
Компьютер с подобными задачами справляется значительно лучше. Тем не менее, с 70-х годов прошлого века, когда ученые начали увлекаться системами технического зрения, впечатляющего прорыва так и не произошло. Сложность задачи явно недооценили - проблема качественного поиска по изображениям остается нерешенной до сих пор.
Традиции
В настоящий момент к вопросу поиска по изображениям традиционные поисковые системы подходят с теми же алгоритмами, что и к поиску по тексту, индексируя только те картинки, которые содержат в своем описании ключевые слова и фразы. Семантический робот – сердце любой поисковой системы – "считывает" текстовое описание изображение (название файла, ссылку с картинки, а также сопроводительный текст на странице вокруг картинки), строит индекс соответствия искомому изображению и располагает вновь найденный объект выше или ниже в результатах поиска в зависимости от степени соответствия поисковому запросу.
Однако проблема заключается в том, что более 99% всех размещенных в интернете изображений не имеют текстовых меток, а за наименование файлов "отвечает" чип в фотоаппарате. Стоит ли говорить, что описать каждое вновь появляющееся в интернете изображение вручную не представляется возможным.
Количество новых изображений, добавляемых в Facebook ежедневно, млн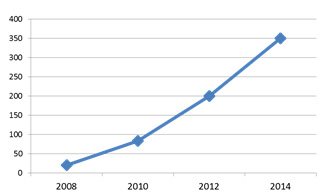
Kuznech, 2012
В результате поисковые роботы ежедневно проходят мимо миллиардов новых изображений, потребитель не может найти интересные и нужные ему картинки, авторы изображений теряют потенциальную аудиторию, а социальные сети, фотохостинги и фотостоки недополучают доходы от рекламы или продажи прав на использование изображений.
Идеи
Если немного помечтать, то можно предположить, что целый ряд индустрий изменится до неузнаваемости, когда появится работающий адекватный, массовый визуальный поиск. База данных Google содержит информацию всего о паре десятков миллиардов изображений, остальные триллионы представляют собой "темную материю" интернета – она занимает дисковое пространство, но доступна только автору и двум-трем его друзьям.
Кто-то скажет, что все эти триллионы изображений ему не нужны, потому что они не представляют никакой ценности. Да, они не нужны, но среди них есть тысячи, которые соответствуют текущим интересам или запросам конкретного человека. Причем запросам не текстовым, а визуальным. Например, разглядывая фотографию современного города, подпирающего небо башнями небоскребов, хочется узнать больше про это место. Десятки тысяч людей уже были там, оставив свои воспоминания на фотохостингах и в социальных сетях, но сейчас приходится заново размещать фотографию, например, на виртуальной стене и спрашивать друзей "кто-нибудь узнает это место?"
Потребители
Очевидно, что круг для применения технологии визуального поиска очень широк: начиная от промышленных задач из области медицины, геологии, безопасности и защиты авторских прав и заканчивая простыми запросами обычных интернет-пользователей. Приведем в пример несколько ситуаций.
В хорошем магазине в торговом центре опытный продавец задаст клиенту пару уточняющих вопросов и предложит несколько вариантов. Интернет-торговля до сих пор не приносит психотерапевтического удовольствия от размеренности в выборе товара - ведь сайты оперируют ограниченным набором категорий и параметров. В свою очередь, визуальный поиск позволяет в качестве шаблона использовать любое изображение, что порой значительно упрощает процесс поиска "такого же, но без крыльев".
В поисковых системах поиск изображения для иллюстрации заметки в социальной сети, блоге или на аватарку устойчиво входит в тройку самых популярных запросов по изображениям. Очевидно, что эффективная система визуального поиска облегчит и упростит его.
Технооснова
Все вышеперечисленное – пока мечты. Чтобы они превратились в реальность, необходима работающая технология, способная быстро – за доли секунды – находить похожие изображения и ранжировать их, как это делает классическая поисковая система с текстовой информацией. При этом не нужны никакие сверхразработки – весь математический аппарат для технического зрения был разработан еще в 80-х годах прошлого века, а технологии обработки огромных массивов информации доступны по лицензии с открытым кодом.
Кроме того, следует научиться индексировать десятки миллиардов изображений – снимая с них "цифровой отпечаток" для дальнейшей идентификации и удаляя оригинал после этого (чтобы не дублировать весь интернет у себя и не нарушать права автора изображения). Эти технологии также отработаны в рамках существующих поисковых систем.
И, наконец, нужна бизнес-модель. Потребители привыкли к тому, что поиск – это бесплатная услуга. Отучать их уже поздно. Значит, нужно найти механизм зарабатывания денег на результатах поиска, благо что они могут представлять и коммерческую ценность.
Реалии рынка
В общей сложности около 50 компаний по всему миру включилось в гонку за главный приз – лидерство в сфере потребительского поиска по изображениям. В частности, молодая питерская компания Kuznech на средства исследовательского гранта Сколково доработала и запустила технологию создания и сравнения "цифровых отпечатков" миллиардов изображений по сотням различных параметров, включая композицию, контрольные точки и линии, цвета, текстуру. Теперь можно задать любую картинку в качестве шаблона для поиска и найти похожие изображения во всей проиндексированной базе.
"Сейчас в тестовой базе Kuznech всего несколько миллионов изображений, - рассказывает Михаил Погребняк, основатель и генеральный директор Kuznech, - мы отрабатываем механизмы похожести, экспериментируем с пользовательским интерфейсом, понятным широкому кругу потребителей. Приходится решать множество вопросов не только технических, но даже из области психологии. Например, женщины и мужчины по-разному определяют понятие визуальной похожести. Это все нужно учитывать".
Основатели Kuznech предполагают в первую очередь использовать свою технологию в партнерстве с крупными фотохостингами, социальными сетями, библиотеками изображений – так легче получить доступ к большим массивам изображений, а также достучаться до широкого круга пользователей, не вкладывая в рекламу.
Результаты поиска могут настраиваться в зависимости от задачи. Например, поиск товаров в интернет-магазине ориентирован на определение ярких четких объектов на белом или однотонном фоне, а поиск иллюстрации для сайта или блога более чувствителен к цветам и текстурам. В перспективе, объединяя визуальные предпочтения потребителя с его социально-демографическими характеристиками можно будет предлагать любому пользователю релевантные и интересные изображения. Частично эту проблему сейчас решает Pinterest – самая быстрорастущая в мире социальная сеть, где пользователи "рассказывают визуальные истории", собирая коллекции любимых изображений и публикуя их для широкого круга своих подписчиков.
Сейчас в карманах миллиардов людей лежат мощные средства создания фото и видео, а системы связи способны за секунды разместить новые данные в практически безграничных сетевых хранилищах. Рост визуального онлайн-контента идет в геометрической прогрессии. По словам Сергея Белоусова, основателя и главного архитектора компании Parallels, если до 2000 года вся человеческая цивилизация накопила около 1 миллиарда изображений, то в июне 2012 года такое же количество размещается в Сети каждые пару часов. "Количество опубликованных в интернете изображений перевалило за 3 триллиона и продолжает расти", - уверен он.
Свои исследовательские подразделения, занимающиеся данной проблематикой, есть в Amazon, Google, Microsoft, Hitachi. Канадская компания Idee уже несколько лет назад запустила свой поисковик по изображениям под названием TinEye с проиндексированным каталогом в 4 миллиарда изображений – он, правда, ориентирован на поиск дубликатов изображений, а не похожих. Это не удивительно, ведь основная специализация материнской компании – защита прав интеллектуальной собственности на изображения в интернете и печатных изданиях. Интересный потребительский продукт на основе поиска похожих изображений предлагает израильский стартап Superfish – пользователь может бесплатно установить плагин к браузеру, который для каждого изображения продукта в интернете будет показывать аналогичные предложения других магазинов – вдруг найдется что-то дешевле. "Тенденция к увеличению предложения программных продуктов в сфере визуального поиска будет только усиливаться, так как именно эта сфера на ближайшие 10 лет станет основным "полем битвы" лидеров ИТ-индустрии, начиная с крупнейших поисковых систем и заканчивая национальными операторами интернет торговли. Тот, кто сумеет грамотнее и быстрее интегрировать визуальный поиск под потребности массового потребителя, получит шанс сохранить или завоевать глобальное лидерство в интернет коммерции, - говорит Александр Потапов, исполнительный директор РВК.
В общем, можно с уверенностью утверждать, что кто бы ни победил в этой гонке, в течение нескольких лет потребительский интернет станет совсем другим – основную массу контента в нем будут составлять изображения и видео, а поисковые системы будут уметь находить нужную пользователю информацию на основе визуальной похожести, а не текстовых описаний. Так, как это делает человеческий мозг.
Из материалов конференции "ИТ в ритейле: новые запросы – новые решения" от 7 февраля 2012 г, проведенной РБК
- Печать
- 0 Комментариев
- 2036 Прочтений
| Поделиться этой статьей | |
| Социальные закладки: |
|
| URL: | |
| BBcode: | |
| HTML: |
- 4.8 (Отлично!) - 5 Голоса
Рейтинг доступен только для пользователей.
Пожалуйста, авторизуйтесьили зарегистрируйтесь для голосования.